class(surveys)[1] "spec_tbl_df" "tbl_df" "tbl" "data.frame" We’ve learned how to create visualisations from the surveys data, but what actually is surveys? R commonly stores tabular data in data.frames, and that is how the surveys data is stored. It’s useful to understand how R thinks about, represents, and stores data in order for us to have a productive working relationship with R.
We can check what surveys is by using the class() function:
class(surveys)[1] "spec_tbl_df" "tbl_df" "tbl" "data.frame" This tells us a smaller amount of information than when we used str(), namely that surveys is ultimately a data.frame.
When we’re looking at large or unfamiliar datasets it’s useful to do some quick checks to get an idea of the kind of data we’re working with. For example, we can look at the first and last 6 rows of our data:
head(surveys)# A tibble: 6 × 13
record_id month day year plot_id species_id sex hindfoot_length weight
<dbl> <dbl> <dbl> <dbl> <dbl> <chr> <chr> <dbl> <dbl>
1 1 7 16 1977 2 NL M 32 NA
2 2 7 16 1977 3 NL M 33 NA
3 3 7 16 1977 2 DM F 37 NA
4 4 7 16 1977 7 DM M 36 NA
5 5 7 16 1977 3 DM M 35 NA
6 6 7 16 1977 1 PF M 14 NA
# ℹ 4 more variables: genus <chr>, species <chr>, taxa <chr>, plot_type <chr>tail(surveys)# A tibble: 6 × 13
record_id month day year plot_id species_id sex hindfoot_length weight
<dbl> <dbl> <dbl> <dbl> <dbl> <chr> <chr> <dbl> <dbl>
1 16873 12 5 1989 8 DO M 37 51
2 16874 12 5 1989 16 RM F 18 15
3 16875 12 5 1989 5 RM M 17 9
4 16876 12 5 1989 4 DM M 37 31
5 16877 12 5 1989 11 DM M 37 50
6 16878 12 5 1989 8 DM F 37 42
# ℹ 4 more variables: genus <chr>, species <chr>, taxa <chr>, plot_type <chr>We can get a useful summary of each numeric variable (column) by using summary():
summary(surveys) record_id month day year plot_id
Min. : 1 Min. : 1.000 Min. : 1.0 Min. :1977 Min. : 1.00
1st Qu.: 4220 1st Qu.: 3.000 1st Qu.: 9.0 1st Qu.:1981 1st Qu.: 5.00
Median : 8440 Median : 6.000 Median :15.0 Median :1983 Median :11.00
Mean : 8440 Mean : 6.382 Mean :15.6 Mean :1984 Mean :11.47
3rd Qu.:12659 3rd Qu.: 9.000 3rd Qu.:23.0 3rd Qu.:1987 3rd Qu.:17.00
Max. :16878 Max. :12.000 Max. :31.0 Max. :1989 Max. :24.00
species_id sex hindfoot_length weight
Length:16878 Length:16878 Min. : 6.00 Min. : 4.00
Class :character Class :character 1st Qu.:21.00 1st Qu.: 24.00
Mode :character Mode :character Median :35.00 Median : 42.00
Mean :31.98 Mean : 53.22
3rd Qu.:37.00 3rd Qu.: 53.00
Max. :70.00 Max. :278.00
NA's :2733 NA's :1692
genus species taxa plot_type
Length:16878 Length:16878 Length:16878 Length:16878
Class :character Class :character Class :character Class :character
Mode :character Mode :character Mode :character Mode :character
Let’s take another look at the structure of surveys using str(). Because we’ve changed a column to factor R will print a second table showing underlying attributes, but we’ll hide that for now.
str(surveys, give.attr=FALSE)spc_tbl_ [16,878 × 13] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
$ record_id : num [1:16878] 1 2 3 4 5 6 7 8 9 10 ...
$ month : num [1:16878] 7 7 7 7 7 7 7 7 7 7 ...
$ day : num [1:16878] 16 16 16 16 16 16 16 16 16 16 ...
$ year : num [1:16878] 1977 1977 1977 1977 1977 ...
$ plot_id : num [1:16878] 2 3 2 7 3 1 2 1 1 6 ...
$ species_id : chr [1:16878] "NL" "NL" "DM" "DM" ...
$ sex : chr [1:16878] "M" "M" "F" "M" ...
$ hindfoot_length: num [1:16878] 32 33 37 36 35 14 NA 37 34 20 ...
$ weight : num [1:16878] NA NA NA NA NA NA NA NA NA NA ...
$ genus : chr [1:16878] "Neotoma" "Neotoma" "Dipodomys" "Dipodomys" ...
$ species : chr [1:16878] "albigula" "albigula" "merriami" "merriami" ...
$ taxa : chr [1:16878] "Rodent" "Rodent" "Rodent" "Rodent" ...
$ plot_type : chr [1:16878] "Control" "Long-term Krat Exclosure" "Control" "Rodent Exclosure" ...The $ in front of each variable acts as an important operator in R. We can use it to select different columns within a data frame. If we type the name of a data frame followed by a $, RStudio will offer tab completion to select a variable within the data from a list by navigating up and down with the arrow keys and hitting enter, or by clicking on the variable you want.
print(surveys$year, max = 20) [1] 1977 1977 1977 1977 1977 1977 1977 1977 1977 1977 1977 1977 1977 1977 1977
[16] 1977 1977 1977 1977 1977
[ reached 'max' / getOption("max.print") -- omitted 16858 entries ]The year column we just printed is referred to as a vector by R. While data.frames are made up of columns and rows, vectors are 1-dimensional series of values. Each column in a data.frame is actually a vector. Vectors are the basic building blocks of all data in R.
There are 4 main types of vectors (also known as atomic vectors):
“character” for strings of characters, like our genus or sex columns. Each entry in a character vector is wrapped in quotes. In other programming languages, this type of data may be referred to as “strings”.
“integer” for integers (whole numbers). You may sometimes see integers represented like 2L or 20L. The L indicates to R that it is an integer, instead of the next data type, “numeric”.
“numeric”, aka “double”, vectors can contain numbers including decimals. Other languages may refer to these as “float” or “floating point” numbers.
“logical” for TRUE and FALSE, which can also be represented as T and F. In other contexts, these may be referred to as “Boolean” data. Note these values are not quoted as R recognises them as logical values.
Vectors can only be of a single type. Since each column in a data.frame is a vector, this means an accidental character following a number, like ‘29i’, can change the type of the whole vector. If you’re working with messy data it’s useful to check the vector types of each column to ensure they are all what you are expecting, otherwise it could indicate a typo in one of the values.
To create a vector from scratch, we can use the c() function, putting values inside, separated by commas.
c(1, 2, 5, 12, 4)[1] 1 2 5 12 4The values get printed out in the console. To store this vector so we can continue to work with it, we need to assign it to an object.
num <- c(1, 2, 5, 12, 4)
class(num)[1] "numeric"We see that num is a numeric vector.
Let’s try making a character vector.
char <- c("apple", "pear", "grape")
class(char)[1] "character"Remember that each entry, like “apple”, needs to be surrounded by quotes, and entries are separated with commas. If you do something like “apple, pear, grape”, you will have only a single entry containing that whole string.
Finally, let’s make a logical vector.
logi <- c(TRUE, FALSE, TRUE, TRUE)
class(logi)[1] "logical"There is an important distinction between 0 and a missing value. A 0 means a 0 was observed, whereas a missing value means there was no observation recorded. R represents missing data as NA, without quotes, in vectors of any type.
Let’s make a numeric vector with an NA value
weights <- c(25, 34, 12, NA, 42)R doesn’t make assumptions about how you want to handle missing data, so if we pass this vector to a numeric function like min() to get the minimum value, it won’t know what to do, so it returns NA.
min(weights)[1] NAThis is a very good thing, since we won’t accidentally forget to consider our missing data. If we decide to exclude our missing values, many basic mathematical functions have an argument to remove them.
min(weights, na.rm = TRUE)[1] 12A common use of vectors is to pass them as arguments in functions. The median() function calculates the median of a a set of values. We also need to set na.rm = TRUE, since there are NA values in the weight column.
median(surveys$weight, na.rm = TRUE)[1] 42Or we could pass this column to hist() to generate a quick histogram of weights, which is useful to check the skew of the data.
hist(surveys$weight)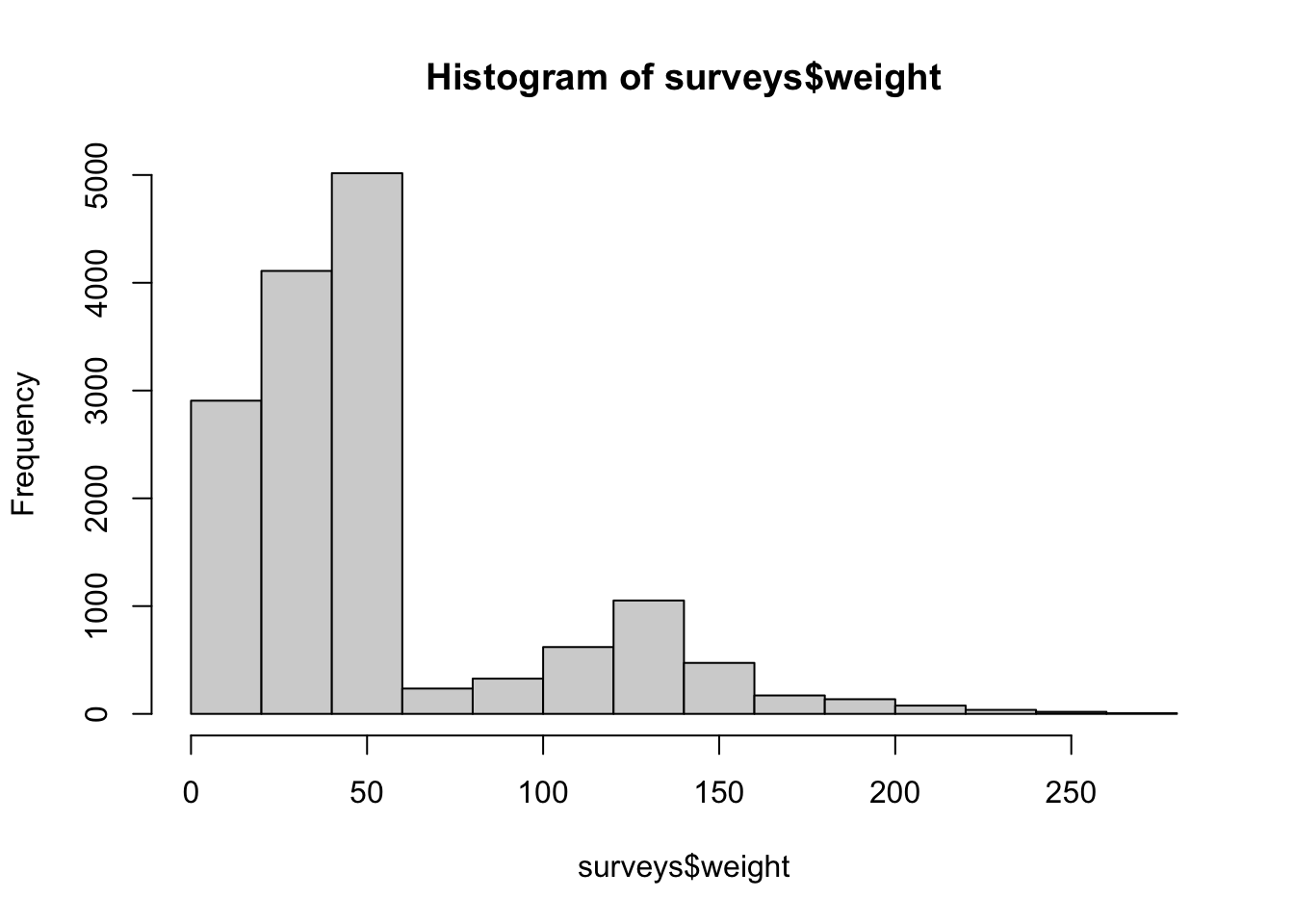
Sometimes we want to generate vectors ourselves, and there are a few functions that can help us to do this.
First, putting : between two numbers will generate a vector of integers starting with the first number and ending with the last.
# Generate 1-10
1:10 [1] 1 2 3 4 5 6 7 8 9 10The seq() function allows you to generate similar sequences, but changing by any amount.
seq(from = 0, to = 1, by = 0.1) [1] 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0seq(from = 0, to = 5, length.out = 11) [1] 0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0Finally, the rep() function allows you to repeat a value, or even a whole vector, as many times as you want, and works with any type of vector.
rep("a", times = 3)[1] "a" "a" "a"rep(1:3, each = 2)[1] 1 1 2 2 3 3Let’s talk about factors because they can be challenging to work with.
In general, it’s best to leave your categorical data as a character (or numeric) vector until you need to use a factor. You might need a factor because:
We can tell R we want a specific column to be a factor by passing the column to the factor() function, and reassigning the result back into the data.frame.
surveys$sex <- factor(surveys$sex)
class(surveys$sex)[1] "factor"Let’s look at the current ordering of the data.
ggplot(surveys, mapping = aes(x = sex, y = weight)) +
geom_boxplot() +
theme_bw()Warning: Removed 1692 rows containing non-finite outside the scale range
(`stat_boxplot()`).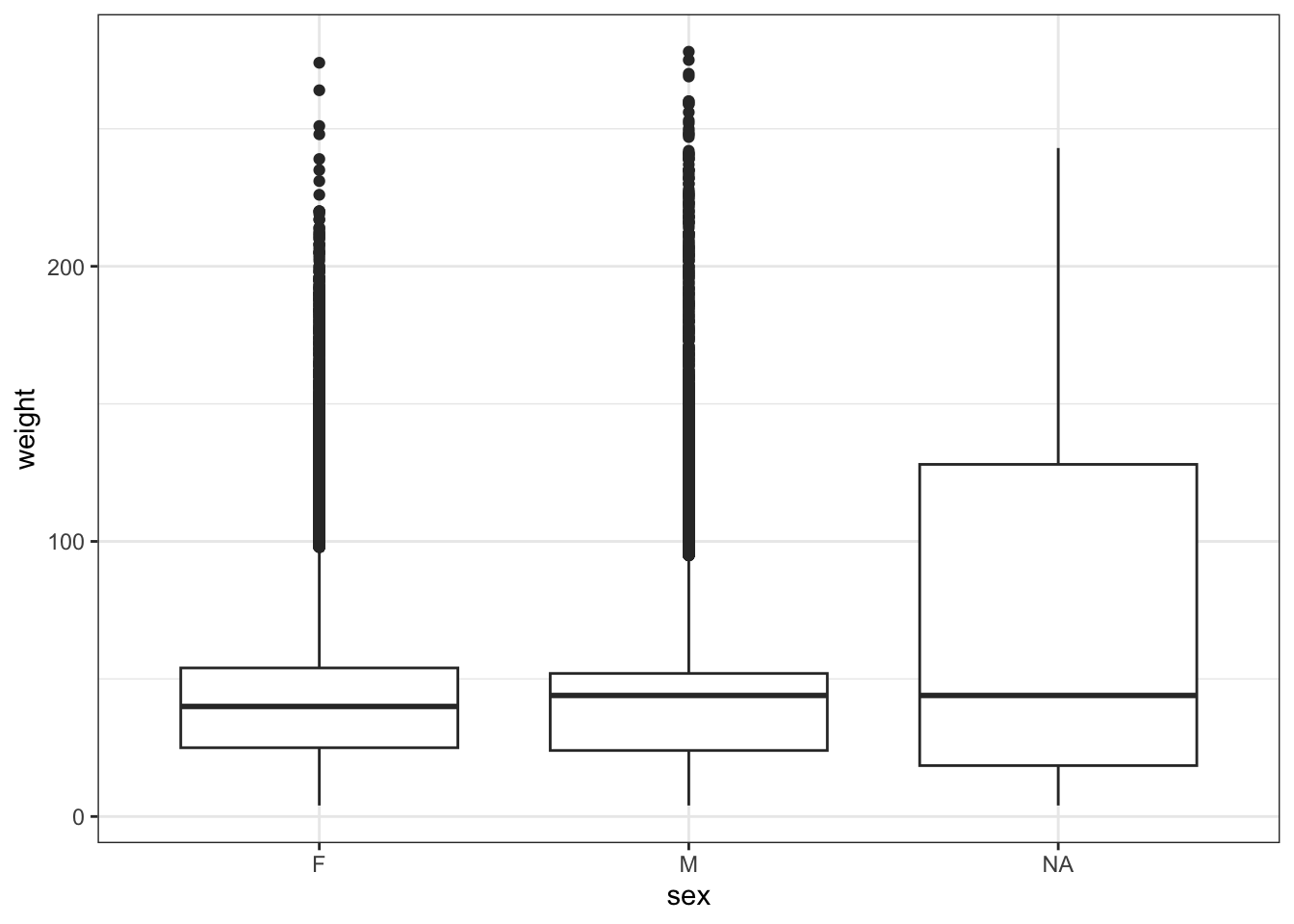
Females are plotted before males.
levels(surveys$sex)[1] "F" "M"Next we’ll use some functions from the forcats package, which we’ve already loaded when we loaded the tidyverse package.
We can change the order of the levels (this can be useful to order the levels on plots).
surveys$sex <- fct_relevel(surveys$sex, c("M", "F"))
levels(surveys$sex)[1] "M" "F"We can confirm this in our plot.
ggplot(surveys, mapping = aes(x = sex, y = weight)) +
geom_boxplot() +
theme_bw()Warning: Removed 1692 rows containing non-finite outside the scale range
(`stat_boxplot()`).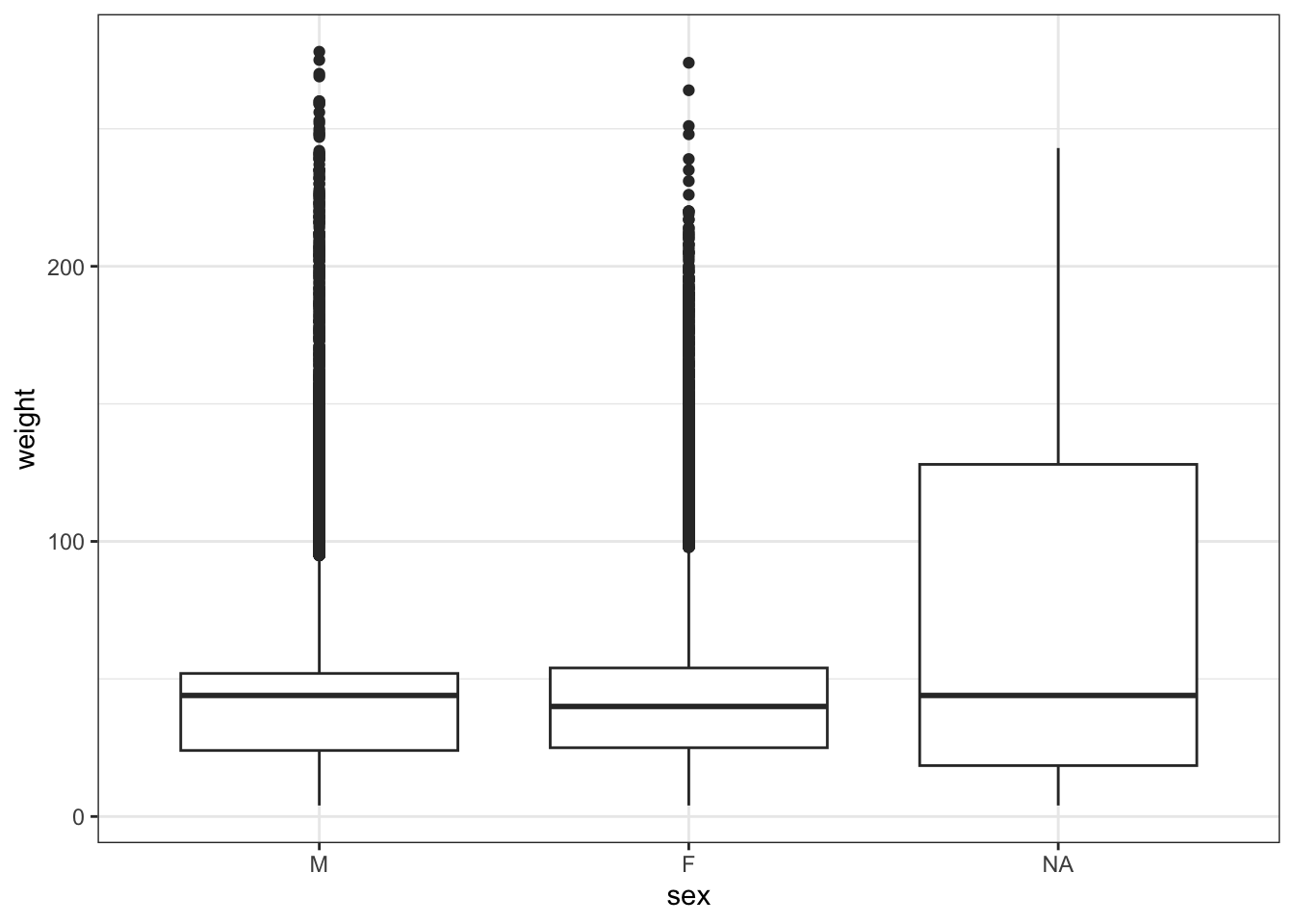
Missing values (NA) are not considered factor levels, so if we want to explicitly have them show up when working with factors we can recode them to a factor level.
surveys$sex <- fct_na_value_to_level(surveys$sex, "unknown")
levels(surveys$sex)[1] "M" "F" "unknown"We can change the names of the factors too.
surveys$sex <- fct_recode(surveys$sex, "male" = "M", "female" = "F")
levels(surveys$sex)[1] "male" "female" "unknown"We can also convert a factor back to a character vector.
surveys$sex <- as.character(surveys$sex)
class(surveys$sex)[1] "character"